07 Mar 2019 ~ 8 min read
How I built a Node.js Service to Clone my AWS S3 Buckets
 Photo by Malte Wingen on Unsplash
Photo by Malte Wingen on Unsplash
Introduction
This project is basically building a Node.js application to clone your AWS S3 buckets locally and recursively.
TBH, this project is a one-liner using the AWS-CLI. Yes, you heard it right. So why are we doing it anyway?
“Why should all the problems must always have only one solution? I simply like more than one. Be it good or bad”
Let’s look at the existing solution first. You install the AWS-CLI and run the following command:
aws s3 cp s3://my-s3-bucket/ ./ --recursive
Surprisingly, apart from using the AWS CLI, I didn't find any proper Node.js script or an app that would do this for medium to large scale buckets using the AWS-SDK. The answers I found on Node.js posts online had several problems, including half-baked scripts, scripts that would try and synchronously create a file and would not know when to complete and also would ignore cloning empty folders if there was any. Basically, it didn't do the job right. Hence decided to write one myself, properly.
I am positive that this would give you a better understanding of how a Node.js application should look and feel, in spite of its size and operation.
TLDR; — Get straight to the code Node-Clone-S3-Bucket
Table of Contents
As I said above, I am not gonna explain the code line-by-line, as I am posting the entire base out. Instead, I will talk about how I have architected the application, with a bit of insight into the core-logic and key features. Let me list out what you can expect and get an idea by the end of this write-up.
- Project Structure of our Application
- Core Logic Surrounding the Application
- Streams in Node.js to Download a File
- Using AWS-SDK to access S3 APIs
- Entire Codebase
Project Structure
There is no opinionated approach for building the project structure, it can change from project to project based on the use case. Personally, I split them into smaller independent modules. One module does one type of task and one type of task only.
Let’s say, if I have a network.js file, it does only network operations and doesn’t modify the file structure or create a new file.
Let’s look at our project structure for instance,
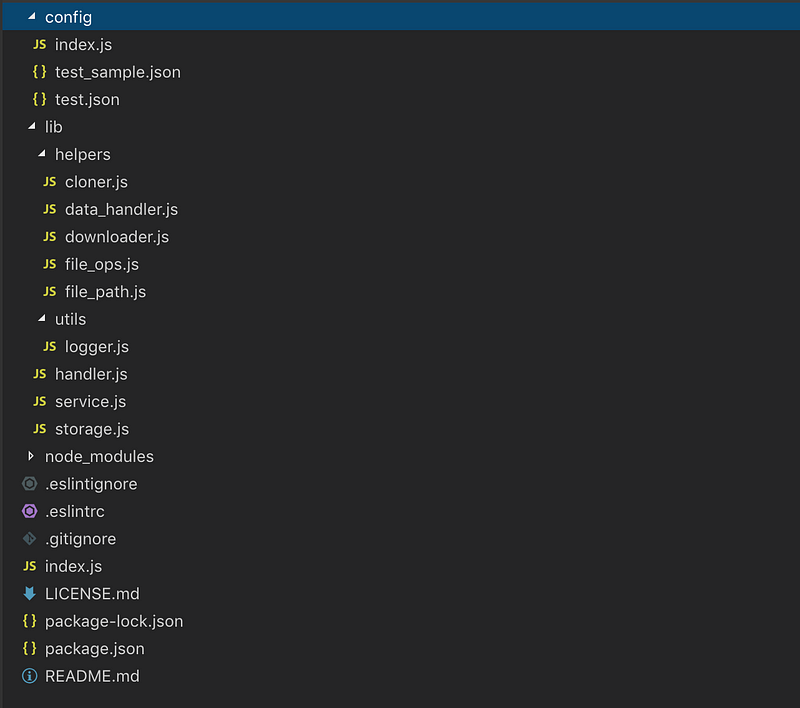 Project Structure
Project Structure
As I said before, there is no particular way to structure your project but its ideal to pick a topic and group all your files under that topic. For me, it was activity, “what does that file handle and how ?”.
Let’s start from the root and go step by step.
Application Dependencies
These are project dependencies and are essential for development and deployment. And are mostly straight forward to understand:
- package.json
- index.js
- git ignore/eslint configs
- license, readme etc.
- node_modules
And then comes the config file, the config file consists of all your application config, apikeys, bucket name, target directory, third party links etc., normally we would have two config files one for production and one for the development environment.
Core Entities
Once we made the skeleton of the application ready with the application dependencies, then we have the core entities. In our application, the Core entities include Handler, Service and Storage.
Handler is where we glue the entire application and create Services, Storages and inject required dependencies and expose an API for the index.js to handle.
Service is where our core-logic of the application lives and all the jobs to other dependencies are delegated from here.
Storage is where all our storage operations take place. In our application S3 is the external storage from where we retrieve our files and data from, hence the AWS-SDK operations exclusively happen only inside this storage module.
Helpers and Utils
When the service starts to run it needs to do all the intended tasks at the same time. For example, in our application, once we get the list of contents under a directory, we need to start creating/cloning the contents locally. This operation is delegated to cloner.js, a helper which is only responsible for cloning the files and folders. The cloner, in turn, needs to access the fileOps.js module to create directories and files.
Under helpers, we have the following files doing their respective chores with or without the help of other helpers.
Cloner, handles the cloning of the files and directories with the help of fileOps module.
Data Handler, maps and parses the data from S3 bucket into a usable or consumable data by the service.
Downloader, only downloads files from S3 bucket and pipes the operation to a write-stream or simply put, takes care of downloading files asynchronously.
fileOps, as the name suggests, uses Node’s fs module to create file-streams and directories.
filePath provides the entire application with the target folder for cloning the S3 bucket’s files and directories and also returns the target bucket and target root directory on the S3.
Logger inside utils returns an instance of Bunyan logger which can be used to send logs to third parties like Kibana.
Core Logic Surrounding the Application
Now that we have done our project setup, let’s look into the core logic of the service module. It involves the sequence of the following actions:
- Fetch the list of Keys from the bucket and the target Prefix. (check AWS-SDK Javascript APIs)
- Separate the files and directories, because we clone the directories and download the files.
- Clone all the directories first, and then move on to download the files.
- Download the files through streams and log success and failure respectively. (AWS-SDK ListKeys API response sometimes ignores giving out directory Keys, hence we need to check for if a directory exists, if not present we create one before downloading the contained file)
Additionally, the service not only clones the entire bucket but also clones only specific folders, without losing the folder tree structure, based on our Prefix configuration as specified here as the rootDirectory for cloning.
Downloading Files Using Streams
Another important concept around the Node.js is using streams to upload and retrieve data from an external source. In our project, the external source is the AWS S3.
When downloading the files we create a read stream from the AWS SDK getObject method and pipe it to a writeStream which will close automatically once all the data is written. The advantage of using streams is the memory consumption, where the application doesn’t care about the size of the file downloaded.
Our code inside storage module as shown below uses streams to asynchronously download the data without blocking the event loop.
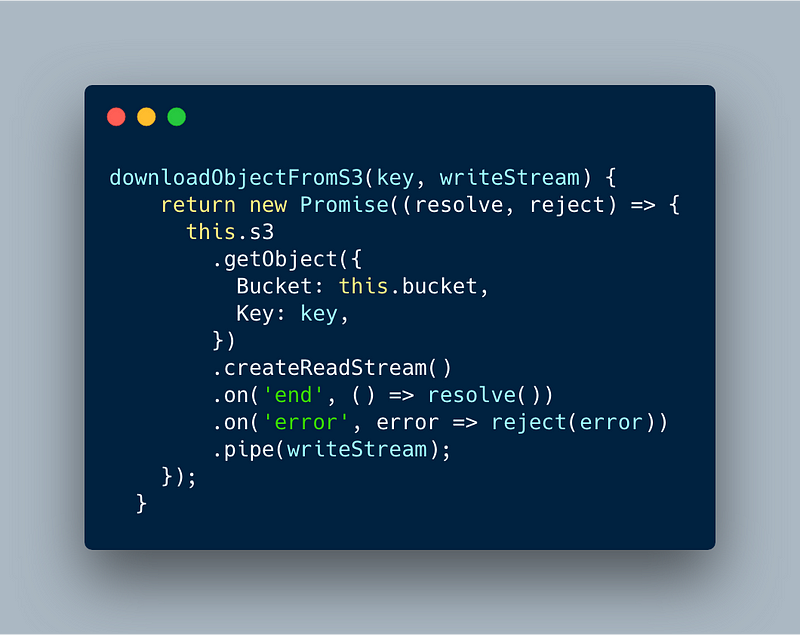 Node.js streams with AWS getObject
Node.js streams with AWS getObject
To dig deeper into Node.js streams, please refer to this write up here.
Using AWS SDK to access S3
This is the most straight forward topic in the whole application, where you install the AWS-SDK and start accessing the methods in it. Taking a look at the storage file would give you a better understanding of how to import and call methods on the same.
The Codebase of the Application.
Here you can find the entire code for this application, more than reading this, hands-on would give a great deal of information and help you understand the core concepts of this application. Feel free to fork it, play with it and if you like it leave a star on the repo.
Conclusion
This marks the end of this write-up, hope it gave a better understanding of how to plan, build and run a Node.js service in real-time on a platform such as AWS.