15 May 2020 ~ 10 min read
How does graphQL work anyway ?
Have you ever wondered how graphQL selectively returns only the data that you specifically requested?
 Interconnected Nodes — Photo by Clint Adair on Unsplash
Interconnected Nodes — Photo by Clint Adair on Unsplash
GraphQL is language-agnostic. And it is more of a concept that can be implemented in any of the supporting languages such as Ruby, Java or Python based on the official specifications. However, in reality, the graphQL implementation, the developer community, and the tooling around the Javascript language is more robust and mature compared to all the other languages. That being said, Javascript/Typescript could be a better language to work with, to get the best out of a lot of available graphQL toolings.
Motivation
To break down the core concepts behind graphQL with the help of graphQL.js by walking through a simple graphQL implementation.
GraphQL Service Overview
In a simple graphQL service, the incoming query is parsed, and the query fields are executed and resolved against the schema to produce the result.
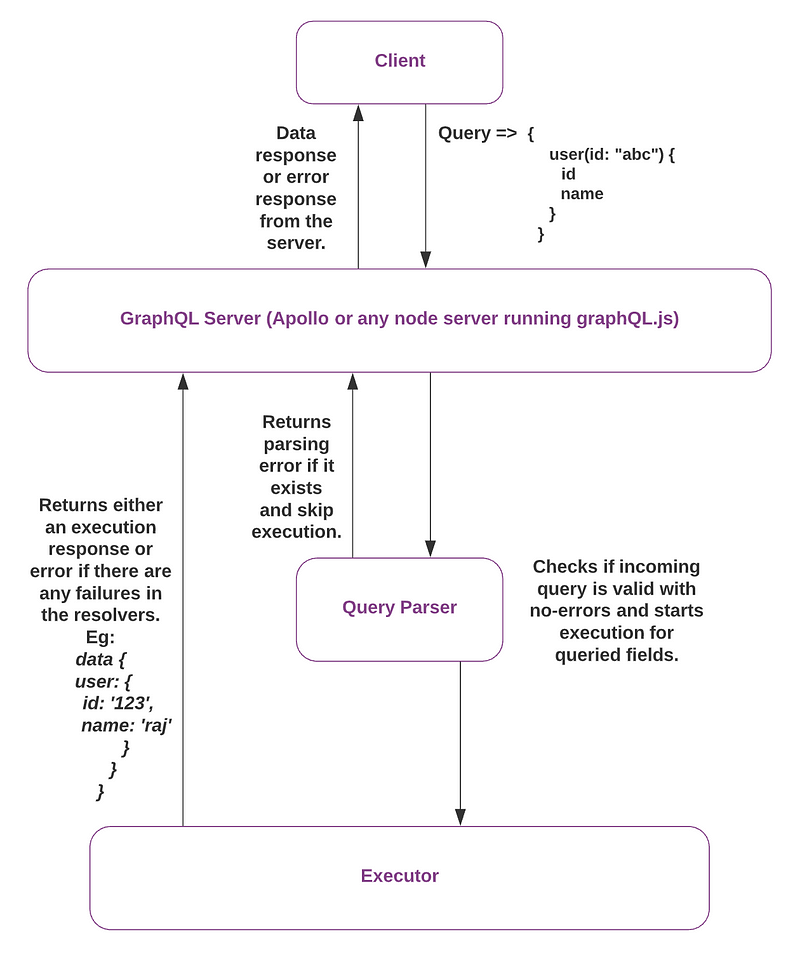 GraphQL Service Overview
GraphQL Service Overview
Building a GraphQL Service
The first step into building and running a graphQL service is to define and build your schema. A schema holds the complete data type and also the data structure information. The schema can be represented in two ways:
- SDL(Schema Definition Language) representation.
- GraphQLSchema object-based representation.
A simple graphQL service using graphql.js
Schema Representation and Conversion
In an ideal world, a graphQL schema is usually represented in the form of an SDL because it makes the schema more human-readable, but in order for the JS environment to understand and execute the SDL as a Javascript code, the SDL schema needs to be converted into an equivalent GraphQLSchema object.
For example, this is the SDL representation of a simple schema:
SDL Representation of Schema
type Person {
name: String
address: String
}
type Query {
person(id: ID): Person
}
The equivalent executable GraphQLSchema object representation of the SDL above would be the following:
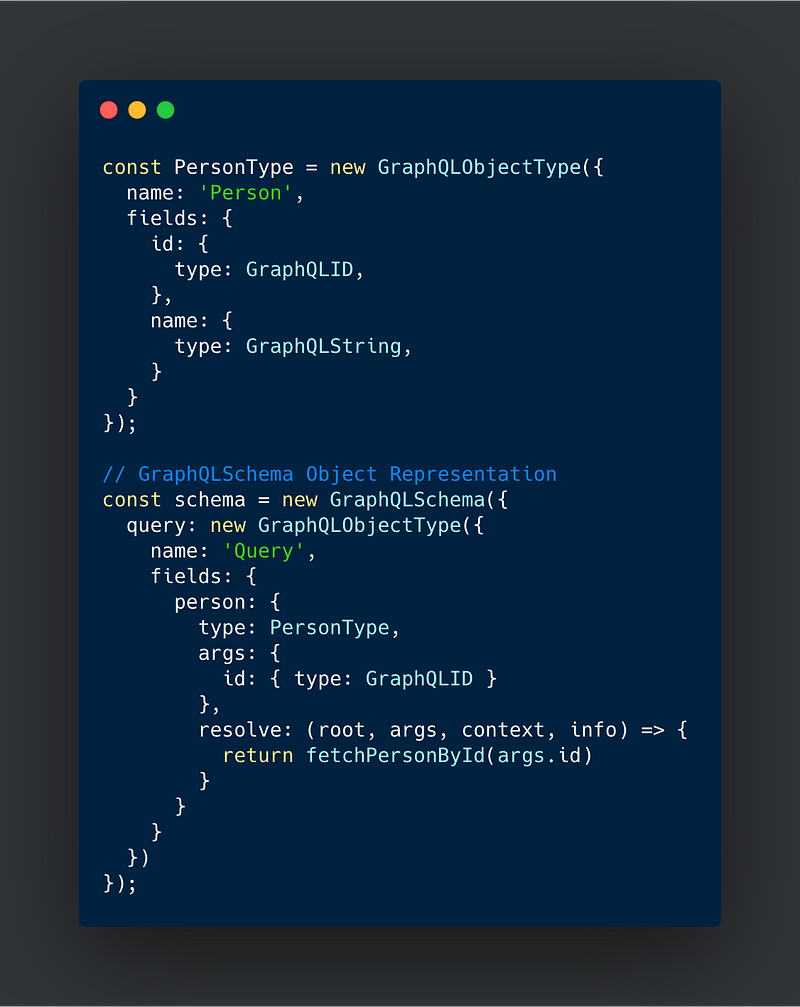 Executable GraphQLSchema Object Representation
Executable GraphQLSchema Object Representation
The graphQL.js’s buildSchema method can convert SDL schema to GraphQLSchema object representation. Conversly, printSchema converts GraphQLSchema object back to SDL schema.
The process of converting an SDL schema into a GraphQLSchema object using the buildSchema method comes with a caveat, once built there will be no resolvers attached to the converted GraphQLSchema object because the SDL schema doesn’t have any knowledge of the resolvers, thereby making the GraphQLSchema object non-executable.
There are two ways to make your GraphQLSchema object executable.
i) Either you can create your own executable GraphQLSchema object, with resolver methods as shown in the image above.
ii) or you can automate the process by using graphQL-tools to combine your typeDefs(SDL) and resolvers together into an executable GraphQLSchema object.
It is also important to keep in mind that the GraphQLSchema constructor doesn’t accept any random type object, in fact, all your types should be constructed first before being used to build the schema. In our case, you can see that we have built a PersonType which is constructed from GraphQLObjectType class. In a similar fashion, you can also construct other types based on their respective class definitions.
Running a GraphQL Service
A valid executable schema is all that you need to run a graphQL service and start listening to the incoming query requests. The entire process of accepting incoming queries and resolving them involves the following steps —
- GraphQL Query Parsing
- GraphQL Query and Schema Validation
- GraphQL Query Execution
GraphQL Query Parsing
The incoming query also comes in a uniquely formatted string which needs to be parsed into a meaningful data-set or a tree (AST) based on graphQL specifications, before they are executed.
GraphQL requires every incoming query field to be resolved separately and it achieves that through the power of ASTs.
Abstract Syntax Trees (ASTs)
ASTs are the core of any graphQL operation. ASTs are nothing but huge JSON trees/objects that are created and managed by AST conversion methods present inside the graphQL.js.
In the code sample below, you can see that we have an incoming graphQL query and the parse method converts the incoming query into an AST for the graphQL execution method to understand.
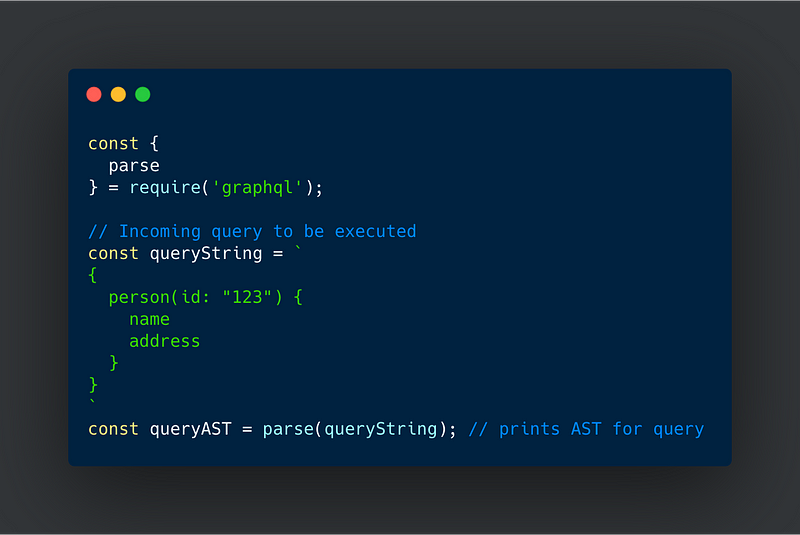 Parsing Incoming Query into an Operation Definition AST
Parsing Incoming Query into an Operation Definition AST
Just a heads-up, the schemas are also converted to AST and are available to us inside the info argument of the resolvers, however, is not important at this point.
Difference between Query AST and Schema AST
Again, this AST is not language-specific or tied to any specific algorithm, anyone can build their custom AST based on their specification sheet and requirements.
A good place to verify the corresponding ASTs for your schemas and queries can be done here on the ASTExplorer website, where you can switch to the graphQL.js section to test the JSON object for your corresponding schema and queries.
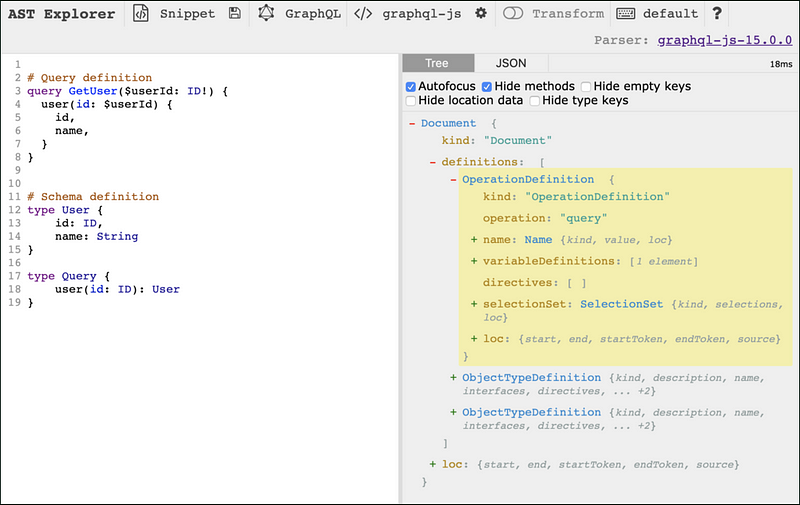 Difference between Query AST and Schema AST
Difference between Query AST and Schema AST
On the left side, you can see that we have a schema represented in form of SDL and a corresponding Query Definition for the schema. And on the right side, you can see that we have an AST tree with two different types of objects with the name OperationDefinition and ObjectTypeDefinition. In fact, these two objects are meant to represent two different ASTs.
The Query-Definition when converted into a AST returns the Operation-Defintion Tree, whereas the Schema-Definition returns the ObjectType-Defintion Tree.
This difference is based on the internal graphQL specifications and the AST conversion algorithms present inside the graphQL.js. For basic query executions, we only need to be concerned about the Query Definition’s AST conversion (queryAST).
GraphQL Query And Schema Validation
Once we have parsed our incoming query into a queryAST. The queryAST is ready for validation and execution against the schema. Although technically, you can execute the query even if only some fields are valid and others not, graphQL explicitly recommends validating query and schema before execution. You can read further on the validation specification from graphQL.
The validation process validates both the schema and the query for duplicate field names, ambiguous fields and other discrepancies. The validation process also validates the schema to see if it contains only the allowed graphQL Type Definitions.
The validator runs through the queryAST and schema and checks the validity of the Document, Operations, Fields, Arguments, Variables, Fragments, Directives and Values. The validation specification is explained in detail with proper examples of how each element is validated based on a set of rules.
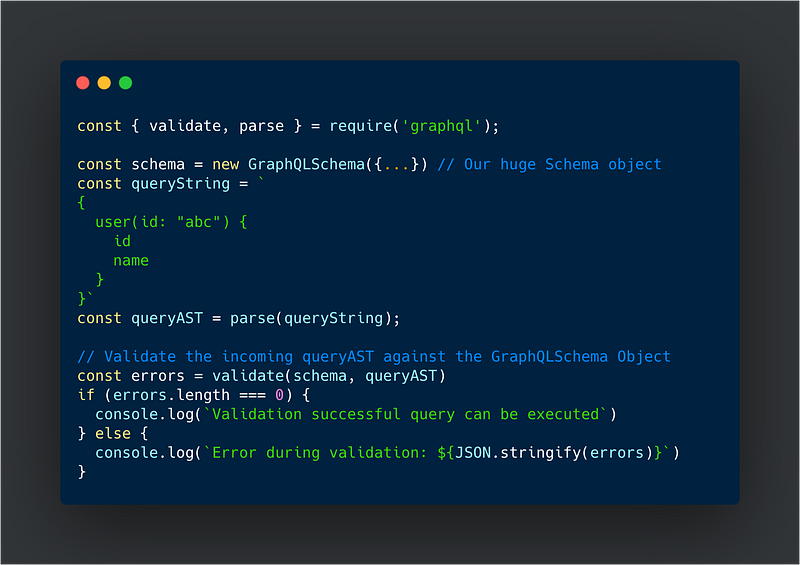 Validate Method from GraphQL.js
Validate Method from GraphQL.js
Although tools like Apollo Server’s graphQL playground automate the validation process for you, it still helps to have a better understanding of the manual validation process.
GraphQL Query Execution 🤯
Once the query is validated without any errors, it’s ready for execution. In order to better understand the execution process I played around with the source code of the graphQL.js and cross-checked the code execution with the graphQL specification sheet for execution, as shown below.
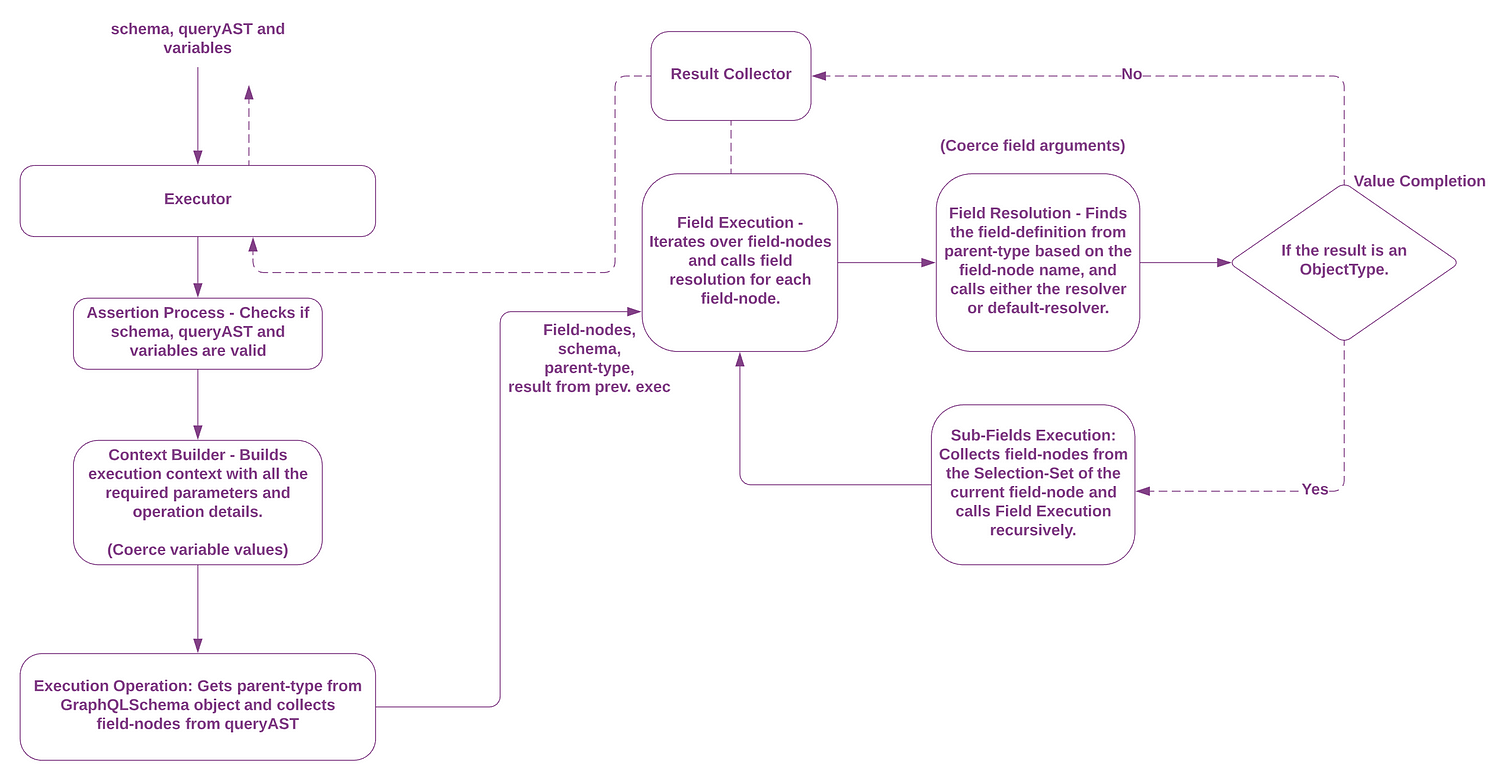
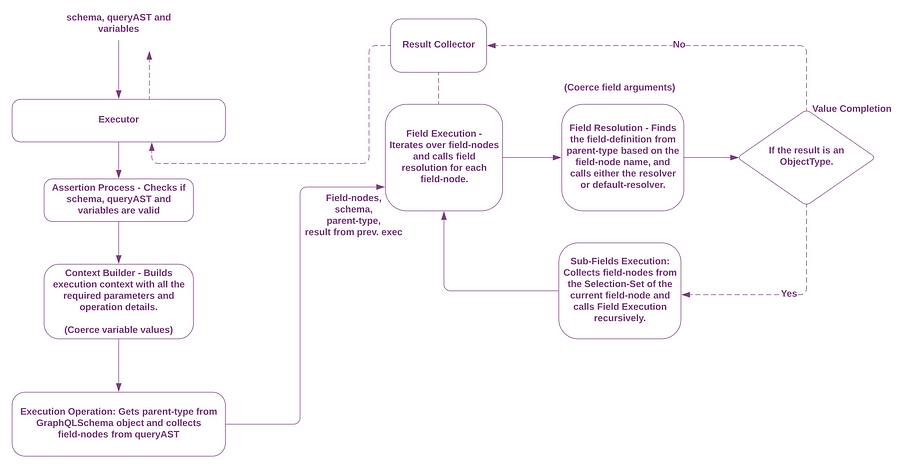 Query Execution Flow Diagram - Detailed Image.
Query Execution Flow Diagram - Detailed Image.
{kind=link}
Based on the flow diagram above, let's look at the query execution process step by step:
Assertion Process
The first step in the execution is the assertion process that quickly validates the schema, queryAST and the variables(if they are passed into execute method). Although the validation process runs in the previous step, graphQL runs it again in case you have not manually validated the schema yourself. The execution process breaks if it encounters any errors.
Building the Execution Context
Once the assertion is complete, the graphQL.js starts building the execution context. During this process, it collects all the required details for the execution such as fragments, operation type from the queryAST and also coerces the variable values if they are present.
Coercion in graphQL.js is similar to Javascript’s coercion but it works based on its own pre-defined set of graphQL scalars specifications.
The built execution context consists of schema, fragments, root value, context value, operation definition, coerced variable values, fieldResolver and errors. For a simple query such as ours, all we need to worry about is the schema and the operation definition from the queryAST.
Execution Operation
The execution operation is the entry point where the field execution starts executing all the requested fields from the incoming query.
**//Incoming Query**
{
person(id: "123") {
id
name
address {
street
city
}
}
}
To kick off the query execution this step prepares two important entities to be passed on to the field-execution step:
i) The first one is the parent-type of the current executing field. For example, if we are executing the person field in the incoming query represented above, then the QueryType is regarded as the parent-type for this field. Similarly, if we are executing the id field then PersonType is considered to be the field’s parent-type.
ii) The next one is the array of field-nodes that are collected from the SelectionSet’s selections of the queryAST’s OperationDefinition.
 OperationDefinition of the QueryAST
OperationDefinition of the QueryAST
Field Execution
Once the array of field nodes and the parent-type information are available for the field then it means that the field is ready for execution. In this step, the array of field nodes are iterated over and the corresponding field names are extracted. These extracted fields-names look up the parent-type for their respective field definitions.
In our case, the person is the first field to be executed and the person field-name would look up it's parent-type i.e the QueryType for extracting its field definition. The field definition consists of all the required information about the field including type, arguments and the resolver. This field definition is passed on to the next step for resolution.
Field Resolution
This operation receives the field definition from the field-execution step. First, the arguments in the field-definition object are coerced. Then the resolver method from the field definition is called with or without the coerced arguments. If there is no resolver method found on the field definition, then a built-in default-resolver would be called in its place. Finally, the result of the resolver execution is passed on to the value-completion step for further execution.
A default-resolver is nothing but a method that returns the field-name from the previously executed result or parent argument of the resolver method.
If we consider our example incoming query above, graphQL.js during resolution of the person field would first coerce its id argument’s value(“123”) and then would call the resolver method to return the result for value-completion.
Value Completion (recursive)
This last step is important because it’s when graphQL decides to either carry out a recursive field execution or store the result. Once the resolved result is obtained for the current executing field from the field-resolution step, graphQL.js then checks to see whether the corresponding field-definition type is an instance of GraphQLObjectType.
If the current field-definition type is an instance of GraphQLObjectType, it means that the resolved result is an object with fields. And as we know that graphQL requires each incoming query field to be resolved separately, the field-execution process is initiated again for the execution of the current field’s sub-fields and the current field’s field-definition type is passed as the parent-type, along with the field-nodes array from the SelectionSet’s selections of the current field-node.
For example, if the person field returns a resolved result of
{id: 1, name: ‘raj’, address {street: ‘one’, city: ‘berlin’}}
then to resolve id, name and address fields respectively, the field-execution is initiated again, with PersonType as the parent-type and the field-nodes array from the SelectionSet’s selections of the person field-node*(refer the Field Execution sub-heading).*
 Person Field Node from QueryAST
Person Field Node from QueryAST
If the current field definition is not at an instance of GraphQLObjectType but an instance of GraphQLScalarType, then the resolved result is collected and stored in an object under the current field-node name as its key. This ensures that the resulting data returned for the query maintains the same order as the query.
 Input Query with the Output Response
Input Query with the Output Response
The recursive field execution process continues until all the fields are resolved up until the points where all the final values are scalar types. The resulting object is then returned if there are no promises found in the resolution result, but if it contains any promises then a promise object is returned which is later resolved into the resulting object, thereby ensuring both synchronous and asynchronous resolver methods can be used.
Note: This process is explained for query execution and it's more or less identical for both mutations and subscriptions with some caveats. For mutations, the field execution happens serially, which means the field-resolution happens one after the other, whereas for queries it happens in parallel, where two or more sibling fields can resolve in any order.
Conclusion
This could be overwhelming at first glance, but once you run the gist locally and start debugging the code, you will gain a better understanding of the entire process. I hope this article was helpful in understanding the basics of graphQL execution.
rajeshdavidbabu/simple-graphql-execution
Further Reading
Everything you need to know about graphQL (good comparison with REST).
If you have plenty of time at your hand complete the full-stack tutorial at the how-to-graphQL website.